平平淡淡的接受这本就属于我的人生,每天不会想太多杞人忧天的事情,累了倒头就睡,醒了就接着继续自己没有走完的路,不再去过多的关注自己的结果,用心感受当下的每一天,感受自己走过的和正在走的路,不颓废,不折磨自己,真好! —知乎(三冬三夏)
写在前面 平平淡淡的接受这本就属于我的人生,每天不会想太多杞人忧天的事情,累了倒头就睡,醒了就接着继续自己没有走完的路,不再去过多的关注自己的结果,用心感受当下的每一天,感受自己走过的和正在走的路,不颓废,不折磨自己,真好! —知乎(三冬三夏)
Linux 60秒分析 下面这个清单适用于任何性能问题的分析工作,也反映了笔者在实际工作中,当登录到一台表现不佳的 Linux 系统中后,在最初60秒内通常会进行的操作。
uptimedmesg | tail && cat /var/log/messagesvmstat 1mpstat -P ALL 1pidstat 1iostat -xz 1free -msar -n DEV 1sar -n tcp,ETCP 1sar -n SOCK 1 3 top
uptime uptime 命令用于显示系统已运行的时间,并提供系统负载平均值的信息。以下是 uptime 命令提供的信息解释:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 ┌──[liruilong@liruilongs.github.io]-[~] └─$man uptime UPTIME(1) User Commands UPTIME(1) NAME uptime - Tell how long the system has been running. SYNOPSIS uptime [options] DESCRIPTION uptime gives a one line display of the following information. The current time, how long the system has been running, how many users are currently logged on, and the system load averages for the past 1, 5, and 15 min‐ utes. This is the same information contained in the header line displayed by w(1). System load averages is the average number of processes that are either in a runnable or uninterruptable state. A process in a runnable state is either using the CPU or waiting to use the CPU. A process in unin‐ terruptable state is waiting for some I/O access, eg waiting for disk. The averages are taken over the three time intervals. Load averages are not normalized for the number of CPUs in a system, so a load average of 1 means a single CPU system is loaded all the time while on a 4 CPU system it means it was idle 75% of the time. ......................................
uptime 可以快速查看当前系统时间以及运行时间,总的登录用户, 以及平均负载:
当前时间:显示执行uptime命令时的系统当前时间。
系统运行时间:显示系统自上次引导或重新启动以来的运行时间。以”X天X小时X分钟”的格式显示。
用户数量:表示当前登录到系统的用户数量。
系统负载平均值:显示过去1分钟、5分钟和15分钟的系统负载平均值。负载平均值代表处于运行状态或等待运行状态的平均进程数量。它指示系统的活动水平和资源利用程度。负载平均值并不针对系统中的CPU核数进行归一化
1 2 3 4 ┌──[root@vms100.liruilongs.github.io]-[~] └─$uptime 11:14:26 up 16 min, 1 user, load average: 21.37, 18.64, 16.25
这里主要关注 平均负载:
在Linux 系统中,这些数字包含了想要在 CPU 上运行的进程,同时也包含了阻塞在不可中断IO(通常是磁盘 I/O)上的进程。这给出了一个高层次视角的资源负载(或者说资源需求)。
3个数字分别是指数衰减的1分钟/5分钟/15分钟滑动窗累积值。通过这3个值可以大致了解负载随时间变化的情况。
快速查看CPU核数可以通过top命令然后按1键查看
1 2 3 4 5 6 7 8 top - 11:21:36 up 23 min, 1 user, load average: 22.36, 19.03, 17.14 Tasks: 443 total, 5 running, 438 sleeping, 0 stopped, 0 zombie %Cpu0 : 6.4 us, 5.4 sy, 0.0 ni, 77.9 id, 0.0 wa, 4.4 hi, 5.9 si, 0.0 st %Cpu1 : 9.2 us, 12.2 sy, 0.0 ni, 71.9 id, 3.6 wa, 2.0 hi, 1.0 si, 0.0 st %Cpu2 : 4.8 us, 3.6 sy, 0.0 ni, 68.8 id, 4.8 wa, 18.0 hi, 0.0 si, 0.0 st %Cpu3 : 4.5 us, 5.5 sy, 0.0 ni, 72.7 id, 2.7 wa, 0.5 hi, 14.1 si, 0.0 st MiB Mem : 15730.5 total, 7489.9 free, 6823.5 used, 1417.2 buff/cache MiB Swap: 2068.0 total, 2068.0 free, 0.0 used. 8496.2 avail Mem
上面的例子显示负载最近有大幅的提升。一般情况下(还受到其他因素的影响,I/O 操作等),负载数与系统 CPU 核数的关系可以用以下规则来理解:
在top命令然后按1键的基础上可以按 t 键对数据进行可视化展示
1 2 3 4 5 6 top - 11:22:26 up 24 min, 1 user, load average: 15.02, 17.58, 16.74 Tasks: 449 total, 19 running, 430 sleeping, 0 stopped, 0 zombie %Cpu0 : 24.5/37.1 62[||||||||||||||||||||||||||||||||||||||||||||||||||||||||| ] %Cpu1 : 15.5/28.0 43[|||||||||||||||||||||||||||||||||||||||| ] %Cpu2 : 37.9/61.1 99[|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| ] %Cpu3 : 15.8/49.7 66[||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| ]
如果负载数小于 CPU 核数的70-80%:这通常表示系统的负载较轻,有足够的处理能力来处理所有的任务。系统响应时间较短,性能较好。
如果负载数接近或超过 CPU 核数的100%:这表示系统的负载很高,正在接近或达到其处理能力的极限。系统可能会出现延迟或变慢的情况,响应时间变长。
如果负载数远远超过 CPU 核数的100%:这表示系统的负载非常高,超过了系统的处理能力。系统可能会出现严重的延迟,甚至崩溃或无法响应。
负载的平均值值得在排障过程中被首先进行检查,以确认性能问题是否还存在。在一个容错的环境中,一台存在性能问题的服务器,在你登录到机器上时,也许已经自动从服务列表中下线了。
一个较高的 15分钟负载与一个较低的1分钟负载同时出现,可能意味着已经错过了问题发生的现场。
1 2 3 4 5 ┌──[root@vms100.liruilongs.github.io]-[~] └─$uptime 11:33:45 up 35 min, 1 user, load average: 1.39, 6.06, 11.64 ┌──[root@vms100.liruilongs.github.io]-[~] └─$
dmesg | tail 或者 cat /var/log/messages或者 journalctl -k | tail 也可以结合 cat /var/log/messages 来排查
1 2 3 4 5 6 7 8 9 10 11 12 ┌──[liruilong@liruilongs.github.io]-[~] └─$dmesg | tail [ 12.216869] vmwgfx 0000:00:0f.0: [drm] Available shader model: SM_5. [ 12.225954] [drm] Initialized vmwgfx 2.20.0 20211206 for 0000:00:0f.0 on minor 0 [ 12.233005] Bluetooth: hci0: unexpected cc 0x0c12 length: 2 < 3 [ 12.233011] Bluetooth: hci0: Opcode 0x c12 failed: -38 [ 12.238757] fbcon: vmwgfxdrmfb (fb0) is primary device [ 12.248762] Console: switching to colour frame buffer device 160x50 [ 12.269448] vmwgfx 0000:00:0f.0: [drm] fb0: vmwgfxdrmfb frame buffer device [ 14.350586] block dm-0: the capability attribute has been deprecated. [ 14.446480] block nvme0n1: No UUID available providing old NGUID [ 14.498286] block nvme0n1: No UUID available providing old NGUID
这个命令显示过去 10 条系统日志,如果有的话。注意在这里寻找可能导致性能问题的错误。 添加 T和t 可以展示对应的时间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ┌──[root@vms100.liruilongs.github.io]-[~] └─$dmesg -T| tail [日 1月 14 10:58:57 2024] vmxnet3 0000:1b:00.0 ens256: NIC Link is Up 10000 Mbps [日 1月 14 10:59:38 2024] device ovs-system entered promiscuous mode [日 1月 14 10:59:39 2024] Timeout policy base is empty [日 1月 14 10:59:39 2024] Failed to associated timeout policy `ovs_test_tp' [日 1月 14 10:59:40 2024] device br-tun entered promiscuous mode [日 1月 14 10:59:40 2024] device br-int entered promiscuous mode [日 1月 14 10:59:40 2024] device ens224 entered promiscuous mode [日 1月 14 10:59:40 2024] device br-ex entered promiscuous mode [日 1月 14 11:03:14 2024] capability: warning: `privsep-helper' uses deprecated v2 capabilities in a way that may be insecure[日 1月 14 11:04:34 2024] hrtimer: interrupt took 11973872 ns ┌──[root@vms100.liruilongs.github.io]-[~] └─$
在日常维护中,往往结合 grep 快速定位问题
1 2 3 4 5 6 7 8 ┌──[root@liruilongs.github.io]-[~] └─$ dmesg -T | grep -i error [五 11月 10 10:32:57 2023] BERT: Boot Error Record Table support is disabled. Enable it by using bert_enable as kernel parameter. ┌──[root@liruilongs.github.io]-[~] └─$ dmesg -T | grep -i warn [五 11月 10 10:32:54 2023] Warning: Intel Processor - this hardware has not undergone upstream testing. Please consult http://wiki.centos.org/FAQ for more information ┌──[root@liruilongs.github.io]-[~] └─$
比如 内存不足引发OOM和TCP 的丢弃`请求的记录。
1 2 3 4 ┌──[root@vms83.liruilongs.github.io]-[~] └─$cat /var/log /messages | grep -i memory Aug 10 20:37:27 vms83 kernel: [<ffffffff81186bd6>] out_of_memory+0x4b6/0x4f0 Aug 10 20:37:27 vms83 kernel: Out of memory: Kill process 25143 (bigmem) score 1347 or sacrifice child
TCP 的相关日志甚至指引了我们下一步的分析方向:查看SNMP 计数器值。
vmstat 1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ┌──[root@liruilongs.github.io]-[~] └─$man vmstat VMSTAT(8) System Administration VMSTAT(8) NAME vmstat - Report virtual memory statistics SYNOPSIS vmstat [options] [delay [count]] DESCRIPTION vmstat reports information about processes, memory, paging, block IO, traps, disks and cpu activity. The first report produced gives averages since the last reboot. Additional reports give information on a sam‐ pling period of length delay. The process and memory reports are instantaneous in either case . ..........................
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ┌──[root@vms100.liruilongs.github.io]-[~] └─$vmstat 1 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 69 0 0 7700836 4204 1441648 0 0 369 101 569 1819 11 35 45 8 0 26 1 0 7711264 4204 1441668 0 0 0 12 1209 1380 9 24 64 3 0 8 0 0 7710592 4204 1441664 0 0 0 27 779 1215 4 11 78 7 0 13 0 0 7699752 4204 1441668 0 0 0 0 766 1313 3 25 72 0 0 31 0 0 7696384 4204 1442288 0 0 0 1412 1157 2928 12 32 49 8 0 60 0 0 7675296 4204 1444292 0 0 0 26 1068 13824 9 26 51 14 0 34 0 0 7670552 4204 1444280 0 0 0 17 798 1514 14 52 34 1 0 60 1 0 7686712 4204 1444508 0 0 0 8 807 2127 6 24 67 3 0 59 2 0 7676624 4204 1445232 0 0 0 8 620 6830 7 66 22 5 0 68 0 0 7677948 4204 1442440 0 0 0 56 1329 3739 13 22 59 7 0 100 0 0 7677920 4204 1442340 0 0 0 21 1030 3778 16 50 29 5 0 19 0 0 7669208 4204 1443220 0 0 0 43 958 3054 19 65 10 6 0 5 2 0 7776028 4204 1445364 0 0 0 40 1124 20039 18 33 44 4 0 84 1 0 7764600 4204 1447240 0 0 0 36 867 23470 14 53 27 5 0 22 0 0 7711224 4204 1447328 0 0 0 112 1353 11900 13 34 50 4 0 36 0 0 7734856 4204 1447572 0 0 0 321 1382 11113 10 22 47 21 0 28 1 0 7738716 4204 1446508 0 0 0 157 889 5779 3 15 64 18 0 30 0 0 7719320 4204 1446696 0 0 0 151 1409 8526 5 27 57 10 0 7 1 0 7713972 4204 1447192 0 0 0 25 1372 23431 13 19 63 5 0 18 0 0 7715444 4204 1447356 0 0 0 56 935 7750 6 19 67 7 0 54 0 0 7766760 4204 1440632 0 0 0 64 1237 4686 11 26 56 7 0 52 0 0 7712752 4204 1441816 0 0 0 4 1265 6567 25 33 42 0 0 ^C ┌──[root@vms100.liruilongs.github.io]-[~] └─$
需要检查的列包括如下几个:
r:CPU上正在执行的和等待执行的进程数量。相比平均负载来说,这是一个更好的排查CPU饱和度的指标,因为它不包含IO。可以这样解释:一个比CPU数量多的 r 值代表 CPU 资源处于饱和状态。free:空闲内存,单位是KB。如果数字位数一眼数不过来,那么内存应该是够用的。使用free -m 命令,可以更好地解释空闲内存。si 和so:页换入和页换出。如果这些值不是零,那么意味着系统内存紧张。这个值只有在配置开启了交换分区后才会起作用。us、sy、id、wa和st:这些都是 CPU运行时间的进一步细分,是对所有的CPU 取平均之后的结果。它们分别代表用户态时间、系统态时间(内核)、空闲率、等待I/O,以及被窃取时间(stolen time,指的是虚拟化环境下,被其他客户机所挤占的时间;或者是Xen 环境下客户机自身隔离的驱动域运行时间)。
上面的例子显示了CPU时间主要花在系统态上。这指引我们下一步将主要针对系统态代码进行剖析。
1 2 3 4 5 6 7 ┌──[root@liruilongs.github.io]-[~] └─$vmstat procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 2 0 0 1057540 2072 1761012 0 0 68 27 1501 595 8 4 87 1 0 ┌──[root@liruilongs.github.io]-[~] └─$
查看CPU平均值,当前系统中,可运行进程为2(r),被阻塞的进程为0(b),系统发生中断次数1501(in),系统发生上下文切换次数为595(cs),系统代码消耗CPU为4%(sy),用户代码消耗CPU为8%(us),系统空闲占比87%(id),剩余1%属于等待IO消耗的CPU空闲状态(wa)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ┌──[root@liruilongs.github.io]-[~] └─$vmstat -s .......... 206387 non-nice user cpu ticks 3 nice user cpu ticks 100381 system cpu ticks 2184710 idle cpu ticks 12604 IO-wait cpu ticks 0 IRQ cpu ticks 4699 softirq cpu ticks 0 stolen cpu ticks ............ 37633050 interrupts 64361523 CPU context switches ........... 210962 forks
这里的ticks为一个时间单位,相关数据为自系统启动时间以来的数据。forks表示系统创建以来的进程数,CPU context switches表示上下文文切换次数,interrupts即中断次数,剩下的参数对应上面的列理解即可,stolen cpu 这个不太理解
mpstat -P ALL l 需要装包
1 2 ┌──[root@vms100.liruilongs.github.io]-[~] └─$yum install -y sysstat
这个命令将每个CPU分解到各个状态下的时间打印出来。
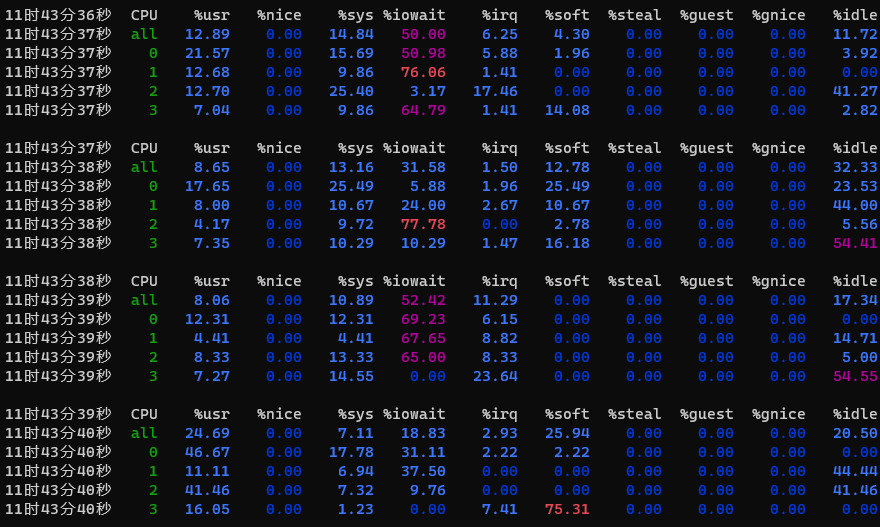
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 ┌──[root@vms100.liruilongs.github.io]-[~] └─$mpstat -P ALL 1 Linux 4.18.0-477.27.1.el8_8.x86_64 (vms100.liruilongs.github.io) 2024年01月14日 _x86_64_ (4 CPU) 11时43分36秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 11时43分37秒 all 12.89 0.00 14.84 50.00 6.25 4.30 0.00 0.00 0.00 11.72 11时43分37秒 0 21.57 0.00 15.69 50.98 5.88 1.96 0.00 0.00 0.00 3.92 11时43分37秒 1 12.68 0.00 9.86 76.06 1.41 0.00 0.00 0.00 0.00 0.00 11时43分37秒 2 12.70 0.00 25.40 3.17 17.46 0.00 0.00 0.00 0.00 41.27 11时43分37秒 3 7.04 0.00 9.86 64.79 1.41 14.08 0.00 0.00 0.00 2.82 11时43分37秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 11时43分38秒 all 8.65 0.00 13.16 31.58 1.50 12.78 0.00 0.00 0.00 32.33 11时43分38秒 0 17.65 0.00 25.49 5.88 1.96 25.49 0.00 0.00 0.00 23.53 11时43分38秒 1 8.00 0.00 10.67 24.00 2.67 10.67 0.00 0.00 0.00 44.00 11时43分38秒 2 4.17 0.00 9.72 77.78 0.00 2.78 0.00 0.00 0.00 5.56 11时43分38秒 3 7.35 0.00 10.29 10.29 1.47 16.18 0.00 0.00 0.00 54.41 11时43分38秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 11时43分39秒 all 8.06 0.00 10.89 52.42 11.29 0.00 0.00 0.00 0.00 17.34 11时43分39秒 0 12.31 0.00 12.31 69.23 6.15 0.00 0.00 0.00 0.00 0.00 11时43分39秒 1 4.41 0.00 4.41 67.65 8.82 0.00 0.00 0.00 0.00 14.71 11时43分39秒 2 8.33 0.00 13.33 65.00 8.33 0.00 0.00 0.00 0.00 5.00 11时43分39秒 3 7.27 0.00 14.55 0.00 23.64 0.00 0.00 0.00 0.00 54.55 11时43分39秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 11时43分40秒 all 24.69 0.00 7.11 18.83 2.93 25.94 0.00 0.00 0.00 20.50 11时43分40秒 0 46.67 0.00 17.78 31.11 2.22 2.22 0.00 0.00 0.00 0.00 11时43分40秒 1 11.11 0.00 6.94 37.50 0.00 0.00 0.00 0.00 0.00 44.44 11时43分40秒 2 41.46 0.00 7.32 9.76 0.00 0.00 0.00 0.00 0.00 41.46 11时43分40秒 3 16.05 0.00 1.23 0.00 7.41 75.31 0.00 0.00 0.00 0.00 11时43分40秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 11时43分41秒 all 24.04 0.00 16.35 12.98 12.50 6.25 0.00 0.00 0.00 27.88 11时43分41秒 0 28.12 0.00 21.88 0.00 31.25 0.00 0.00 0.00 0.00 18.75 11时43分41秒 1 21.67 0.00 20.00 0.00 20.00 11.67 0.00 0.00 0.00 26.67 11时43分41秒 2 7.58 0.00 16.67 16.67 6.06 1.52 0.00 0.00 0.00 51.52 11时43分41秒 3 46.00 0.00 8.00 32.00 0.00 10.00 0.00 0.00 0.00 4.00
对于比较高的 %iowait(等待I/O操作完成占用CPU的百分比,表示CPU时间用于等待I/O操作完成的百分比。) 时间也要注意,可以使用磁盘 I/O工具进一步分析
如果出现较高的 %sys 值(系统态占用),可以使用系统调用(syscall)跟踪和内核跟踪,以及CPU剖析等手段进一步分析。
%idle指CPU的空闲率,通过检查单个热点(繁忙)CPU,挑出一个可能的线程扩展性问题
上面的输出暴露了一个问题:CPU0 的用户态的占比高达 100%,这是单个线程遇到瓶颈的特征。
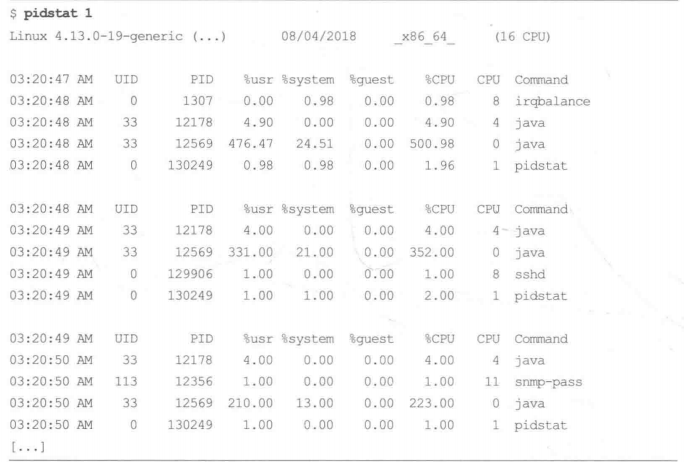
pidstat 1 pidstat(1)命令按每个进程展示 CPU的使用情况(包括用户态和系统态时间的分解)。top(l)命令虽然也很流行,但是pidstat(1)默认支持滚动打印输出,这样可以采集到不同时间段的数据变化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 ┌──[root@vms100.liruilongs.github.io]-[~] └─$pidstat 3 Linux 4.18.0-477.27.1.el8_8.x86_64 (vms100.liruilongs.github.io) 2024年01月14日 _x86_64_ (4 CPU) 11时31分10秒 UID PID %usr %system %guest %wait %CPU CPU Command 11时31分13秒 0 14 0.00 1.99 0.00 1.66 1.99 0 rcu_sched 11时31分13秒 0 33 0.00 0.66 0.00 0.00 0.66 3 ksoftirqd/3 11时31分13秒 0 718 0.00 0.33 0.00 2.65 0.33 3 kworker/3:3-events 11时31分13秒 0 970 1.99 0.66 0.00 0.33 2.65 0 tuned 11时31分13秒 42435 2133 0.66 0.00 0.00 0.66 0.66 2 neutron-dhcp-ag 11时31分13秒 42407 2134 0.33 0.00 0.00 0.00 0.33 2 cinder-schedule 11时31分13秒 42435 2137 0.66 0.33 0.00 0.33 0.99 0 neutron-openvsw 11时31分13秒 42435 2182 0.33 0.00 0.00 0.33 0.33 3 neutron-metadat 11时31分13秒 42418 2437 0.99 0.33 0.00 0.99 1.32 0 heat-engine 11时31分13秒 42415 2842 0.66 0.99 0.00 0.66 1.66 0 glance-api 11时31分13秒 42436 2936 0.99 0.00 0.00 0.66 0.99 3 nova-conductor ................................................ .................................... 平均时间: 42436 9819 0.33 0.00 0.00 1.50 0.33 - nova-conductor 平均时间: 42418 9951 0.17 0.50 0.00 0.00 0.66 - heat-engine 平均时间: 42418 9952 0.17 0.00 0.00 0.17 0.17 - heat-engine 平均时间: 0 24178 0.00 0.17 0.00 0.00 0.17 - sshd 平均时间: 42435 42662 0.33 0.17 0.00 0.33 0.50 - neutron-l3-agen 平均时间: 0 79775 0.17 0.66 0.00 0.00 0.83 - pidstat ┌──[root@vms100.liruilongs.github.io]-[~] └─$
这个输出显示了一个Java 进程每秒使用的CPU 资源在变化:这个百分比是对全部CPU相加的和因此500%相当于5个100%运行的CPU。
iostat -xz 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ┌──[root@vms100.liruilongs.github.io]-[~] └─$iostat -xz Linux 4.18.0-477.27.1.el8_8.x86_64 (vms100.liruilongs.github.io) 2024年01月14日 _x86_64_ (4 CPU) avg-cpu: %user %nice %system %iowait %steal %idle 10.78 0.00 36.46 20.39 0.00 32.37 Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util nvme0n1 101.86 23.92 4143.65 729.07 0.07 0.98 0.07 3.92 33.62 38.59 4.35 40.68 30.48 5.10 64.21 nvme0n2 0.55 0.00 15.62 0.00 0.00 0.00 0.00 0.00 28.66 0.00 0.02 28.50 0.00 19.27 1.06 scd0 0.05 0.00 0.01 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.17 0.00 0.56 0.00 dm-0 87.79 24.64 3865.46 718.38 0.00 0.00 0.00 0.00 37.96 42.92 4.39 44.03 29.16 5.59 62.87 dm-1 0.51 0.00 11.59 0.00 0.00 0.00 0.00 0.00 4.50 0.00 0.00 22.65 0.00 4.58 0.23
这个工具显示了存储设备的IO 指标。要检查的列包括如下几个。
r/s、w/s、rkB/s和 wkB/s:这些是每秒向设备发送的读、写次数,以及读、写字节数。可以用这些指标对业务负载画像。某些性能问题仅仅是因为超过了能够承受的最大负载导致的。await:I/O 的平均响应时间,以毫秒为单位。这是应用需要承受的时间,它同时包含了I/O 队列时间和服务时间。超过预期的平均响应时间,可看作设备已饱和或者设备层面有问题的表征。aqu-sz\avgqu-sz:设备请求队列的平均长度。比1大的值有可能是发生饱和的表征(不过对有些设备,尤其是对基于多块磁盘的虚拟设备来说,通常以并行方式处理请求)。%util:设备使用率。这是设备繁忙程度的百分比,显示了每秒设备开展实际工作的时间占比。不过它展示的并不是容量规划意义下的使用率,因为设备可以并行处理请求。大于60%的值通常会导致性能变差(可以通过await(完成对一个请求的服务所需的平均时间(按毫秒计),该平均时间为请求在磁盘队列中等待的时间加上磁盘对其服务所需的时间) 字段确认),不过这也取决于具体设备。接近 100% 的值通常代表了设备达到饱和状态。
iostat的扩展磁盘统计信息:
统计数据
说明
rrqm/s
在提交给磁盘前,被合并的读请求的数量
wrqm/s
在提交给磁盘前,被合并的写请求的数量
r/s
每秒提交给磁盘的读请求数量
w/s
每秒提交给磁盘的写请求数量
rsec/s
每秒读取的磁盘扇区数
wsec/s
每秒写入的磁盘扇区数
rkB/s
每秒从磁盘读取了多少KB的数据
wkB/s
每秒向磁盘写入了多少KB的数据
avgrq-sz
磁盘请求的平均大小(按扇区计)
avgqu-sz
磁盘请求队列的平均大小。
await
完成对一个请求的服务所需的平均时间(按毫秒计),该平均时间为请求在磁盘队列中等待的时间加上磁盘对其服务所需的时间
svctm
提交到磁盘的请求的平均服务时间(按毫秒计)。该项表明磁盘完成一个请求所花费的平均时间。与await不同,该项不包含在队列中等待的时间
%util
利用率
当avgqu-sz的值特别大的时候,且请求等待时间await远远高于请求服务svctm所花费时间,且利用率%util为100%的时候,表明该磁盘处于饱和状态。
这有时会引起困惑,比如当iostat(1)报告说某个设备已经达到100%的使用率后,还能够接受更高的负载。它只是报告某个设备在一段时间内100%繁忙,并没有说设备的使用率达到100%了:此时也许仍然可以接受更高的负载。在一个卷后面有多个磁盘设备支撑的情况下由于可以并行处理请求,iostat(1)中的%util这个指标就更加具有迷惑性。
free -m 1 2 3 4 5 ┌──[root@vms100.liruilongs.github.io]-[~] └─$free -m total used free shared buff/cache available Mem: 15730 7564 6440 52 1725 7754 Swap: 2067 0 2067
这个输出显示了用兆字节(MB)作为单位的可用内存。检查可用内存 (available)是否接近0;这个值显示了在系统中还有多少实际剩余内存可用,包括缓冲区和页缓存区。将一些内存用于缓存可以提升文件系统的性能。可以根据不同的参数更换单位
1 2 3 4 5 6 7 ┌──[root@vms100.liruilongs.github.io]-[~] └─$free -g total used free shared buff/cache available Mem: 15 7 6 0 1 7 Swap: 2 0 2 ┌──[root@vms100.liruilongs.github.io]-[~] └─$
sar -n DEV 1 显示每个设备发送和接收的数据包数和字节数信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 ┌──[root@vms100.liruilongs.github.io]-[~] └─$sar -n DEV 1 Linux 4.18.0-477.27.1.el8_8.x86_64 (vms100.liruilongs.github.io) 2024年01月14日 _x86_64_ (4 CPU) 11时40分16秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil 11时40分17秒 lo 17.54 17.54 0.98 0.98 0.00 0.00 0.00 0.00 11时40分17秒 ens160 50.88 58.77 3.79 4.07 0.00 0.00 0.88 0.00 11时40分17秒 ens224 224.56 0.00 18.85 0.00 0.00 0.00 1.75 0.00 11时40分17秒 ens256 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 11时40分17秒 ovs-system 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 11时40分17秒 br-tun 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 11时40分17秒 tap9f7d35c5-15 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 11时40分17秒 br-int 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 11时40分17秒 br-ex 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 ^C 平均时间: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil 平均时间: lo 22.94 22.94 1.29 1.29 0.00 0.00 0.00 0.00 平均时间: ens160 50.22 51.08 3.70 4.32 0.00 0.00 0.87 0.00 平均时间: ens224 224.24 0.00 18.70 0.00 0.00 0.00 1.30 0.00 平均时间: ens256 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 平均时间: ovs-system 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 平均时间: br-tun 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 平均时间: tap9f7d35c5-15 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 平均时间: br-int 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 平均时间: br-ex 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 ┌──[root@vms100.liruilongs.github.io]-[~] └─$
列
说明
rxpck/s
数据包接收速率
txpck/s
数据包发送速率
rxkB/s
kb接收速率
txkB/s
kb发送速率
rxcmp/s
压缩包接收速率
txcmp/s
压缩包发送速率
rxmcst/s
多播包接收速率
显示每个设备的发送和接收错误信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ┌──[root@vms81.liruilongs.github.io]-[~/ansible] └─$sar -n EDEV 1 1 Linux 3.10.0-693.el7.x86_64 (vms81.liruilongs.github.io) 2022年05月14日 _x86_64_ (2 CPU) 22时53分07秒 IFACE rxerr/s txerr/s coll/s rxdrop/s txdrop/s txcarr/s rxfram/s rxfifo/s txfifo/s 22时53分08秒 ens32 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 22时53分08秒 cali86e7ca9e9c2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 22时53分08秒 cali13a4549bf1e 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 22时53分08秒 cali5a282a7bbb0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 22时53分08秒 cali12cf25006b5 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 22时53分08秒 cali45e02b0b21e 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 22时53分08秒 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 22时53分08秒 calicb34164ec79 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 22时53分08秒 tunl0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 22时53分08秒 docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 平均时间: IFACE rxerr/s txerr/s coll/s rxdrop/s txdrop/s txcarr/s rxfram/s rxfifo/s txfifo/s 平均时间: ens32 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 平均时间: cali86e7ca9e9c2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 平均时间: cali13a4549bf1e 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 平均时间: cali5a282a7bbb0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 平均时间: cali12cf25006b5 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 平均时间: cali45e02b0b21e 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 平均时间: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 平均时间: calicb34164ec79 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 平均时间: tunl0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 平均时间: docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 ┌──[root@vms81.liruilongs.github.io]-[~/ansible] └─$
列
说明
rxerr/s
接收错误率
txerr/s
发送错误率
co11/s
发送时的以太网冲突率
rxdrop/s
由于Linux内核缓冲区不足而导致的接收帧丢弃率
txdrop/s
由于Linux内核缓冲区不足而导致的发送帧丢弃率
txcarr/s
由于载波错误而导致的发送帧丢弃率
rxfram/s
由于帧对齐错误而导致的接收帧丢弃率
rxfifo/s
由于FIFO错误而导致的接收帧丢弃率
txfifo/s
由于FIFO错误而导致的发送帧丢弃率
显示使用套接字(TCP、UDP和RAW)的总数信息
1 2 3 4 5 6 7 8 9 10 11 ┌──[root@vms81.liruilongs.github.io]-[~/ansible] └─$sar -n SOCK 1 3 Linux 3.10.0-693.el7.x86_64 (vms81.liruilongs.github.io) 2022年05月14日 _x86_64_ (2 CPU) 22时56分23秒 totsck tcpsck udpsck rawsck ip-frag tcp-tw 22时56分24秒 3487 245 9 0 0 163 22时56分25秒 3487 245 9 0 0 165 22时56分26秒 3487 245 9 0 0 167 平均时间: 3487 245 9 0 0 165 ┌──[root@vms81.liruilongs.github.io]-[~/ansible] └─$
列
说明
totsck
当前正在被使用的套接字总数
tcpsck
当前正在被使用的TCP套接字总数
udpsck
当前正在被使用的UDP套接字总数
rawsck
当前正在被使用的RAW套接字总数
ip-frag
IP分片的总数
sar -n TCP,ETCP 1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 ┌──[root@vms100.liruilongs.github.io]-[~] └─$sar -n TCP,ETCP 1 Linux 4.18.0-477.27.1.el8_8.x86_64 (vms100.liruilongs.github.io) 2024年01月14日 _x86_64_ (4 CPU) 11时39分24秒 active/s passive/s iseg/s oseg/s 11时39分25秒 0.00 0.00 16.50 16.50 11时39分24秒 atmptf/s estres/s retrans/s isegerr/s orsts/s 11时39分25秒 0.00 0.00 0.00 0.00 15.53 11时39分25秒 active/s passive/s iseg/s oseg/s 11时39分26秒 0.00 0.00 5.00 5.00 11时39分25秒 atmptf/s estres/s retrans/s isegerr/s orsts/s 11时39分26秒 0.00 0.00 0.00 0.00 4.00 ................................. ^C 平均时间: active/s passive/s iseg/s oseg/s 平均时间: 0.00 0.00 17.82 17.82 平均时间: atmptf/s estres/s retrans/s isegerr/s orsts/s 平均时间: 0.00 0.00 0.00 0.00 16.83 ┌──[root@vms100.liruilongs.github.io]-[~] └─$
使用sar(1)工具来查看 TCP 指标和TCP 错误信息。相关的字段包括如下几个。
active/s:每秒本地发起的 TCP连接的数量(通过调用connect0)创建)。passive/s:每秒远端发起的 TCP连接的数量(通过调用accept0创建)。retrans/s:每秒TCP 重传的数量。orsts/s:每秒的连接重置数。表示每秒钟发生的连接重置次数。atmptf/s:每秒的连接尝试次数。表示每秒钟有多少个连接尝试被发起。estres/s:每秒建立的连接数。表示每秒钟成功建立的连接数。
主动和被动连接计数对于业务负载画像很有用。重传则是网络或者远端主机有问题的征兆。
top 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ┌──[root@vms100.liruilongs.github.io]-[~] └─$top top - 11:46:44 up 8 min, 1 user, load average: 6.52, 17.45, 10.38 Tasks: 449 total, 1 running, 448 sleeping, 0 stopped, 0 zombie %Cpu(s): 0.9 us, 1.1 sy, 0.0 ni, 96.8 id, 0.0 wa, 0.6 hi, 0.5 si, 0.0 st MiB Mem : 15730.5 total, 7503.6 free, 7147.4 used, 1079.5 buff/cache MiB Swap: 2068.0 total, 2068.0 free, 0.0 used. 8177.7 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 1947 42418 20 0 555196 132972 20272 S 1.3 0.8 0:12.86 heat-engine 10320 42436 20 0 540276 122200 17492 S 1.3 0.8 0:08.95 nova-scheduler 949 root 20 0 694072 31640 16876 S 1.0 0.2 0:16.58 tuned 1945 42415 20 0 749212 142564 34988 S 1.0 0.9 0:12.38 glance-api 1965 42436 20 0 540120 121848 17324 S 1.0 0.8 0:12.16 nova-conductor 15567 root 20 0 269540 5228 4160 R 1.0 0.0 0:00.05 top ..........................................
以 top 命令作为结束,对相关结果进行二次确认,并能够浏览系统和进程的摘要信息运气好的话,这个60 秒分析过程会帮助你找到一些性能问题的线索。
可以通过 t 键和 m 对数据进行可视化展示
1 2 3 4 5 6 7 8 9 10 11 12 13 top - 19:32:22 up 2 days, 3:01, 1 user, load average: 0.00, 0.02, 0.05 Tasks: 237 total, 2 running, 235 sleeping, 0 stopped, 0 zombie %Cpu0 : 0.0/0.0 0[ ] %Cpu1 : 0.0/0.0 0[ ] %Cpu2 : 0.0/0.3 0[ ] %Cpu3 : 0.0/0.0 0[ ] %Cpu4 : 0.0/0.0 0[ ] %Cpu5 : 0.0/0.0 0[ ] %Cpu6 : 0.0/0.0 0[ ] %Cpu7 : 0.0/0.0 0[ ] KiB Mem : 14.9/8154892 [|||||||||||||| ] KiB Swap: 0.0/0 [ ]
博文部分内容参考 © 文中涉及参考链接内容版权归原作者所有,如有侵权请告知,这是一个开源项目,如果你认可它,不要吝啬星星哦 :)
《BPF Performance Tools》
© 2018-至今 liruilonger@gmail.com , All rights reserved. 保持署名-非商用-相同方式共享(CC BY-NC-SA 4.0)